Single-node optimisation for LSDCatchmentModel
I run the LSDCatchmentModel (soon to be released as HAIL-CAESAR package…) on the ARCHER supercomputing facility on single compute nodes. I.e. one instance of the program per node, using a shared-memory parallelisation model (OpenMP). Recently, I’ve being trying to find the optimum setup of CPUs/Cores/Threads etc per node. (While trying not to spend too much time on it!). Here are some of the notes:
Compiler choice
I will write this up as a more detailed post later, but all these tests are done using the Cray compiler, a license for which is available on the ARCHER HPC. In general I’ve found this offers the best performance over the intel and gnu compilers, but more investigation is warranted.
The executable LSDCatchmentModel.out was compiled with the -O2 level of optimisation and the hstd=c++11 compiler flag.
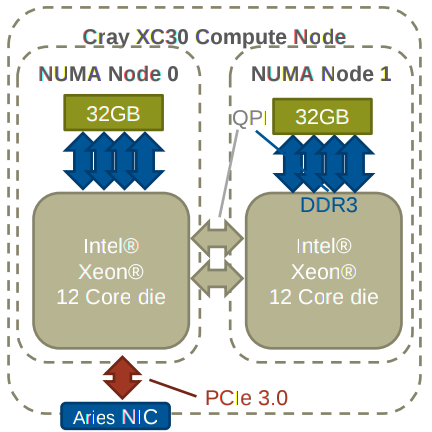
ARCHER compute nodes
Each node on ARCHER consists of two Intel Xeon processors, each with 32GB of memory. (So 64GB in total for the whole node, which either processor can access). Each one of these CPUs, with its corresponding memory, forms what is called a NUMA node or NUMA-region. It is generally much faster for a CPU to access its local NUMA node memory, but the full 64GB is available. Accessing the “remote” NUMA region will have higher latency and may slow down performance.
Options for Optimisation
Programs on ARCHER are launched with the aprun command, which requests the number of resources you want and their configuration. There are a vast number of options/arguments you can specify with this command, but I’ll just note the important ones here:
-n [NUMBER] - The number of “Processing Elements”, i.e. the number of instances of your executable. Just running a single 1 in this case.
-d [NUMBER] - The number of “CPUs” to use for the program. Here a CPU refers to any core or virtual core. On the ARCHER system, each physcial processor has 12 physical cores, so a total of 24 “CPUs” in total. I use “CPU” hereafter. With Intel’s special hyperthreading technology turned on, you actually get double the number of logical CPUs, so 48 CPUs in total.
-j 2 - Turns on hyperthreading as above. Default is off (-j 1, but no need to specify if you want to leve it off.)
-sn [1 or 2] the number of NUMA regions to use per program. You can limit the CPUS that are allocated to a single NUMA node, which may (or may not) give you a performance boost. by default processes are allocated on a single NUMA node until it is full up, then it moves on to the next one.
-ss “Strict segmentation’. Means that each CPU is limited to accessing the local 32GB of memory and cannot be allocated more than 32GB. If more than 32GB is needed, the program will crash.
-cc [NUMBER OR RANGE] CPU affinity, i.e. which CPUs to allocate to. Each logical CPU on the compute node has a number [0-23] or [0-47] with hyperthreading turned on. The numbering of CPUs is slightly counterintuitive. The first physical processor has CPUs [0-11] and [24-36] if hyperthreading is turned on. The second physical processor has CPUs numbered [12-23] and [37-48] if hyperthreading is turned on.
A typical aprun command looks like this: aprun -n 1 -d 24 -j 2 ./LSDCatchmentModel.out ./directory paramfile.params
Best options
ARCHER recommend to use only a single NUMA node when running OpenMP programs (i.e. don’t spread processes between physcial processors) but actually I have found for many cases, LSDCatchmentModel get the best performance increase from maxing out the number of CPUs, and turning on hyperthreading in some cases. There is not one rule, however, and different datasets can have different optimum compute node settings. For the small boscastle catchment, for example, running aprun -n 1 -d 48 -j 2 ... produced the fastest model run, which is contrary to what ARCHER recommend. (They suggest not turning on hyperthreading as well, for example.
OpenMP threads
OpenMP threads are not the same thing as CPUs. If you have 24 CPUs for example, your program will not automatically create 24 threads. In fact on ARCHER the default is just one thread! You can set this before you run aprun with: export OMP_NUM_THREADS=24 or however many you want. I haven’t really experimented with having different amounts of threads to availble CPUs, so normally I just set threads to the same number of CPUs requested with the -d option.

